在當(dāng)今以客戶體驗為核心競爭力的時代,卓越的技術(shù)服務(wù)不僅是產(chǎn)品價值的延伸,更是企業(yè)贏得信任與忠誠的關(guān)鍵。華為,作為全球領(lǐng)先的ICT基礎(chǔ)設(shè)施和智能終端提供商,其強大且高效的客戶服務(wù)體系是其成功的基石之一。其中,ITR(Issue to Resolution,問題到解決)流程體系,是華為技術(shù)服務(wù)能力的核心骨架與神經(jīng)系統(tǒng)。它不僅僅是一個處理故障的流程,更是一個貫穿問題受理、處理、升級、閉環(huán)全周期的端到端客戶價值管理模型。
一、ITR流程的核心定位與價值
ITR流程在華為內(nèi)部與IPD(集成產(chǎn)品開發(fā))、LTC(線索到回款)并列為三大核心業(yè)務(wù)流程。如果說IPD負(fù)責(zé)“造好產(chǎn)品”,LTC負(fù)責(zé)“賣好產(chǎn)品”,那么ITR的核心使命就是“用好產(chǎn)品”,確保客戶在購買后獲得持續(xù)、可靠、高效的服務(wù)支持,最大化產(chǎn)品生命周期價值。其核心價值體現(xiàn)在:
- 提升客戶滿意度與忠誠度:快速響應(yīng)和解決客戶問題,將每一次故障轉(zhuǎn)化為增強客戶信任的機會。
- 驅(qū)動產(chǎn)品與服務(wù)質(zhì)量改進:通過流程系統(tǒng)性地收集、分析一線問題,反哺IPD流程,推動產(chǎn)品設(shè)計與質(zhì)量的持續(xù)優(yōu)化。
- 優(yōu)化服務(wù)資源與效率:標(biāo)準(zhǔn)化、自動化的流程減少了重復(fù)勞動和溝通成本,提升了服務(wù)工程師的解決效率與協(xié)同能力。
- 構(gòu)建知識資產(chǎn):將解決過程沉淀為可復(fù)用的知識案例,賦能全球服務(wù)團隊,實現(xiàn)能力快速復(fù)制。
二、ITR流程體系的詳細(xì)架構(gòu)與運作
華為的ITR流程是一個結(jié)構(gòu)嚴(yán)謹(jǐn)、角色清晰、工具支撐的完整系統(tǒng),通常可以分為以下幾個關(guān)鍵階段:
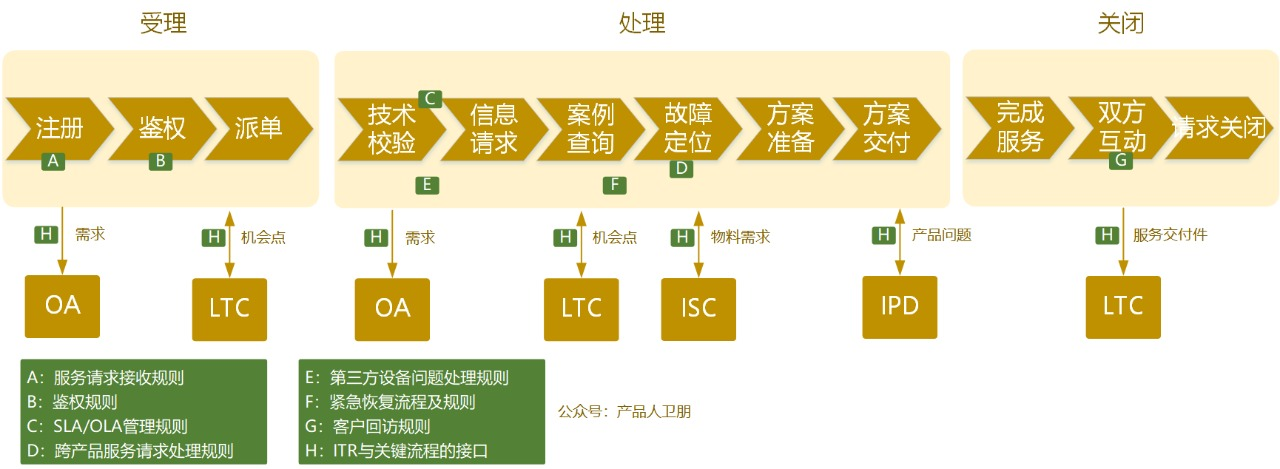
階段一:服務(wù)請求受理與分派
客戶通過熱線電話、在線門戶、郵件或客戶經(jīng)理等多種渠道提交問題。一線受理中心(如全球技術(shù)支持中心)會進行初步的受理、記錄和分類,并基于問題的類型、緊急程度、影響范圍以及預(yù)設(shè)的SLA(服務(wù)等級協(xié)議),通過IT系統(tǒng)(如集成服務(wù)管理平臺)自動或手動分派給最合適的后端技術(shù)支持工程師或現(xiàn)場工程師。確保“對的問題,在承諾的時間內(nèi),找到對的人”。
階段二:問題診斷與處理
工程師接到任務(wù)后,首先會利用知識庫、診斷工具和歷史案例進行問題定位與分析。華為強大的知識管理系統(tǒng)(KMS)和智能工具(如故障診斷機器人)在此階段發(fā)揮巨大作用,能顯著提升首次解決率。工程師遵循標(biāo)準(zhǔn)化的方法進行故障排除和修復(fù)。
階段三:升級與協(xié)同
當(dāng)問題超出當(dāng)前工程師或團隊的解決能力、范圍,或涉及重大客戶影響時,流程會觸發(fā)升級機制。這可能包括:
- 技術(shù)升級:向更高級別的技術(shù)專家或研發(fā)團隊求助。
- 管理升級:當(dāng)問題可能引發(fā)客戶嚴(yán)重投訴或商業(yè)風(fēng)險時,通知客戶經(jīng)理、服務(wù)管理層乃至公司高層,進行資源協(xié)調(diào)和客戶溝通。
清晰的升級路徑和協(xié)同規(guī)則,確保復(fù)雜問題不被擱置,資源能得到高效整合。
階段四:解決、確認(rèn)與閉環(huán)
問題得到解決后,工程師需將解決方案更新到工單,并主動反饋給客戶進行確認(rèn)。客戶確認(rèn)問題解決后,工單進入閉環(huán)階段。但ITR的閉環(huán)不僅是關(guān)閉一個工單,更重要的是:
- 經(jīng)驗與知識沉淀:將本次處理的過程、根因分析、解決方案形成標(biāo)準(zhǔn)化案例,錄入知識庫,供全球共享。
- 根本原因分析(RCA):對于重大或重復(fù)發(fā)生的問題,啟動根因分析流程,找出系統(tǒng)性原因,并推動產(chǎn)品、流程或服務(wù)的改進項目,防止問題再次發(fā)生,實現(xiàn)從“救火”到“防火”的轉(zhuǎn)變。
三、支撐ITR流程高效運轉(zhuǎn)的關(guān)鍵要素
- 強大的數(shù)字化平臺:集成化的服務(wù)管理云平臺是ITR的“操作臺”,實現(xiàn)了從受理到閉環(huán)的全流程在線化、可視化、可管理。
- 全球統(tǒng)一的知識庫:這是ITR的“智慧大腦”,凝聚了全球工程師的經(jīng)驗,是提升效率和解決質(zhì)量的核心資產(chǎn)。
- 明確的角色與職責(zé)(RASIC矩陣):每個流程環(huán)節(jié)都定義了誰負(fù)責(zé)(Responsible)、誰批準(zhǔn)(Approve)、誰支持(Support)、通知誰(Informed)、咨詢誰(Consult),確保權(quán)責(zé)清晰,協(xié)作順暢。
- 以SLA為導(dǎo)向的績效管理:將流程的關(guān)鍵指標(biāo)(如首次響應(yīng)時間、解決時間、客戶滿意度CSAT)與團隊和個人績效掛鉤,驅(qū)動流程高效執(zhí)行。
- 持續(xù)優(yōu)化的流程機制:ITR流程本身也需要通過審計、回顧和度量進行持續(xù)優(yōu)化,以適應(yīng)業(yè)務(wù)變化和技術(shù)發(fā)展。
四、對產(chǎn)品經(jīng)理與技術(shù)服務(wù)團隊的啟示
華為ITR流程體系深刻詮釋了“人人都是產(chǎn)品經(jīng)理”的內(nèi)涵,尤其對技術(shù)服務(wù)團隊和產(chǎn)品經(jīng)理而言:
- 對產(chǎn)品經(jīng)理:ITR是獲取用戶真實反饋的“金礦”。產(chǎn)品經(jīng)理應(yīng)主動關(guān)注ITR流程中反饋的高頻問題、難點問題,將其作為產(chǎn)品迭代和體驗優(yōu)化最直接的輸入。好的產(chǎn)品經(jīng)理必須關(guān)注產(chǎn)品的“全生命周期”,而不僅僅是上市前的階段。
- 對技術(shù)服務(wù)團隊:ITR流程要求工程師不僅是技術(shù)專家,更是流程的執(zhí)行者和知識的貢獻者。需要具備客戶溝通、流程遵循、知識管理和協(xié)作的綜合能力。技術(shù)服務(wù)的目標(biāo)從“解決當(dāng)前問題”升維到“預(yù)防未來問題”和“提升客戶體驗”。
****
華為的ITR流程體系,是一個將客戶聲音轉(zhuǎn)化為內(nèi)部改進動力的精密引擎。它超越了傳統(tǒng)售后服務(wù)的范疇,構(gòu)建了一個以客戶問題為起點,以客戶滿意和產(chǎn)品進步為終點的價值創(chuàng)造閉環(huán)。在數(shù)字化轉(zhuǎn)型的浪潮下,任何致力于提供卓越產(chǎn)品和服務(wù)的組織,深入研究并借鑒這樣一套端到端、數(shù)據(jù)驅(qū)動、持續(xù)優(yōu)化的流程體系,都將獲得至關(guān)重要的核心競爭力。它告訴我們,卓越的服務(wù),始于一個被認(rèn)真對待的問題,成于一套科學(xué)高效的解決系統(tǒng)。